Article complet sur les Sets en Python, tout ce qu’il y a à savoir
Tim
December 2nd, 2024
En Python, les Sets sont des structures de données puissantes et flexibles, idéales pour manipuler des collections d’éléments uniques et non ordonnés. Elles sont particulièrement utiles pour éliminer les doublons, effectuer des opérations d’ensemble, et analyser des données efficacement. À travers cet article, vous découvrirez comment tirer parti de ces ensembles pour simplifier votre code et résoudre des problèmes complexes. Prêt à explorer cette fonctionnalité incontournable ? Allons-y !
Création de Sets en Python
Une fois n'est pas coutume, en Python La création de sets est simple : on utilise des accolades {} pour les définir. Les éléments du set peuvent être de différents types, mais ils doivent être immuables.
Exemples :
# Création d'un set d'entiers
dates_historiques = {1789, 1492, 1976, 1969, 1989}
print(dates_historiques) # Affiche: {1969, 1492, 1989, 1976, 1789}
# Création d'un set de chaînes de caractères
ordinateur = {"uc", "ecran", "clavier", "souris"}
print(ordinateur) # Affiche: {'uc', 'clavier', 'ecran', 'souris'}
# Création d'un set vide
set_vide = set()
print(set_vide) # Affiche: set()Opérations sur les Sets
Python offre une panoplie d’opérations puissantes pour manipuler les sets :
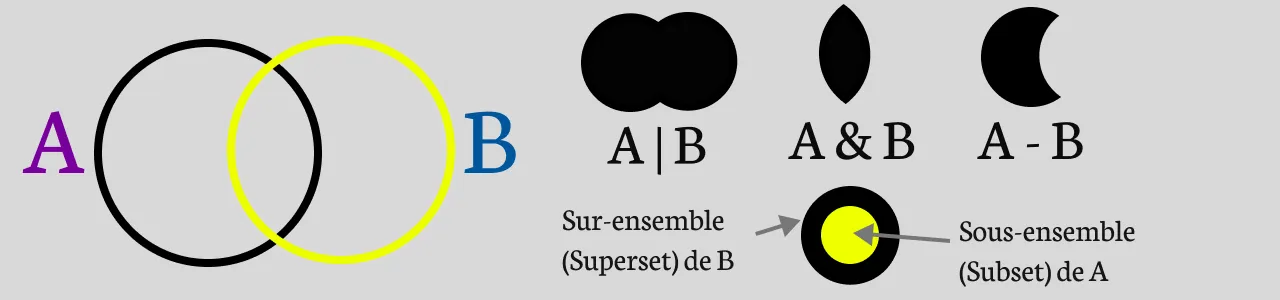
1. Ajout et Suppression d’éléments
Ajouter un élément : La méthode
add()permet d’ajouter un élément au set.Supprimer un élément : La méthode
remove()permet de supprimer un élément. Si l’élément n’est pas présent, elle lève une erreur. La méthodediscard()est plus sûre : si l’élément est absent, elle ne lève pas d’erreur.
Exemple :
vetements = {'chapeau', 'chemise', 'tee-shirt', 'calecon'}
# Ajout d'un élément
vetements.add('veste')
print(vetements) # Affiche: {'tee-shirt', 'chemise', 'veste', 'chapeau', 'calecon'}
# Suppression d'un élément
vetements.remove('chapeau')
print(vetements) # Affiche: {'tee-shirt', 'chemise', 'veste', 'calecon'}
# Suppression d'un élément (si présent)
vetements.discard('calecon')
print(vetements) # Affiche: {'veste', 'tee-shirt', 'chemise'}2. Union, Intersection et Différence
Union : L’opérateur
|(ou la méthodeunion()) retourne un nouveau set contenant tous les éléments des deux sets.Intersection : L’opérateur
&(ou la méthodeintersection()) retourne un nouveau set contenant les éléments communs aux deux sets.Différence : L’opérateur
-(ou la méthodedifference()) retourne un nouveau set contenant les éléments présents dans le premier set mais pas dans le second.
Exemple :
fruits = {'pomme', 'cerise', 'banane', 'kiwi', 'Tomate'}
legumes = {'haricot vert', 'carotte', 'pomme de terre', 'Tomate'}
# Union
fruits_ou_legumes = fruits | legumes
print(fruits_ou_legumes) # Affiche: {'Tomate', 'cerise', 'kiwi', 'pomme de terre', 'pomme', 'haricot vert', 'carotte', 'banane'}
# Intersection
fruits_et_legumes = fruits & legumes
print(fruits_et_legumes) # Affiche: {'Tomate'} car c'est le seul qui est dans fruits et légumes en même temps
# Différence
difference_set = fruits - legumes
print(difference_set) # Affiche: {'kiwi', 'pomme', 'banane', 'cerise'}. Tomate n'est pas inclus car il est aussi un légume3. Sous-Ensemble et Sur-Ensemble
Sous-Ensemble : L’opérateur
<=(ou la méthodeissubset()) vérifie si tous les éléments d’un set sont présents dans un autre set.Sur-Ensemble : L’opérateur
>=(ou la méthodeissuperset()) vérifie si tous les éléments d’un set sont présents dans un autre set.Vérification de l’Appartenance : La méthode
inpermet de vérifier si un élément est présent dans un set.
Exemple :
chiens_allemands = {'Berger Allemand', 'Doberman', 'Rottweiler'}
chiens = {'Berger Allemand', 'Labrador', 'Beagle', 'Doberman', 'Rottweiler', 'Bulldog'}
# Sous-Ensemble (Vérifie si toutes les races de chiens allemands sont dans l'ensemble des chiens)
print(chiens_allemands <= chiens) # Affiche: True, car toutes les races allemandes sont dans l'ensemble des chiens
print(chiens_allemands.issubset(chiens)) # Affiche: True, car chiens_allemands est un sous-ensemble de chiens
# Sur-Ensemble (Vérifie si l'ensemble des chiens contient toutes les races de chiens allemands)
print(chiens >= chiens_allemands) # Affiche: True, car l'ensemble des chiens contient toutes les races allemandes
print(chiens.issuperset(chiens_allemands)) # Affiche: True, car chiens est un sur-ensemble de chiens_allemands
# Test d'inclusion pour une race spécifique
print('Labrador' in chiens) # Affiche: True, car le Labrador fait partie de l'ensemble des chiens
print('Bulldog' in chiens_allemands) # Affiche: False, car le Bulldog n'est pas une race allemandeApplications Pratiques des Sets en Python
Les Sets s’avèrent être un outil indispensable dans divers contextes :
Suppression des Doublons
Lorsqu’on gère des données, il est fréquent d’avoir des éléments dupliqués, notamment dans des listes d’adresses e-mail ou d’identifiants. Les sets sont la solution parfaite pour résoudre ce problème, car ils ne tolèrent pas de doublons.
Prenons un exemple d’une liste d'adresses email contenant des doublons. En utilisant un set, nous pouvons facilement extraire des adresses uniques sans affecter la lisibilité ou l’efficacité du code.
Exemple :
emails = ['alice@example.com', 'bob@example.com', 'alice@example.com', 'charlie@example.com', 'bob@example.com']
# Suppression des doublons d'adresses email
emails_uniques = set(emails)
print(emails_uniques) # Affiche: {'charlie@example.com', 'alice@example.com', 'bob@example.com'}Dans cet exemple, nous avons une liste d'adresses e-mails avec des répétitions. En transformant la liste en un set, les doublons sont automatiquement supprimés, et on obtient uniquement les adresses uniques.
Traitement de Données
Les sets sont très utiles pour des tâches de traitement de données telles que :
Calculer des statistiques : Le nombre d’éléments uniques, la fréquence des valeurs, etc.
Analyser des relations entre des ensembles de données.
Filtrer et classer des informations.
Conclusion : Les Sets en Python, un atout précieux
C'est déjà fini. Nous avons donc vu que les sets sont une structure de données polyvalente et efficace en Python. Ils simplifient la manipulation de collections d’éléments uniques et ouvrent un large éventail de possibilités pour diverses tâches de programmation. En comprenant bien leurs concepts et leurs opérations, vous êtes prêt à les utiliser à bon escient et ainsi tirer pleinement parti de leur puissance.